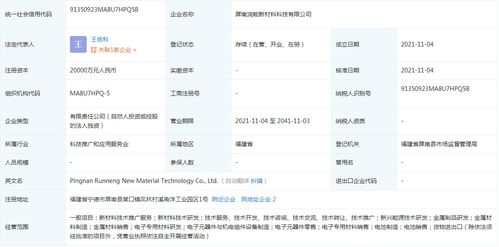
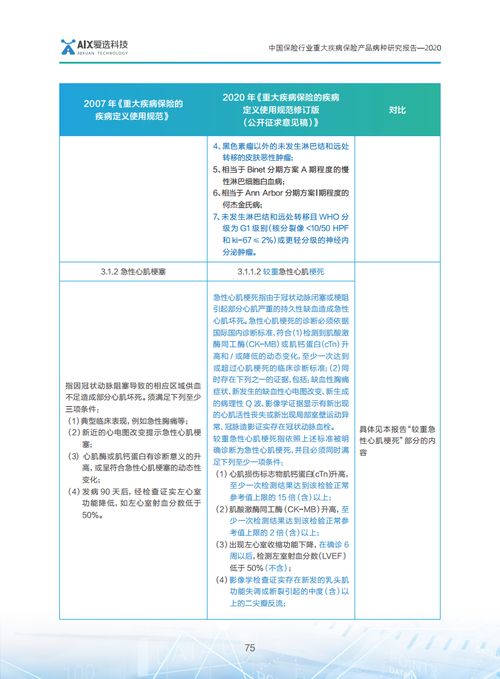
前廳部的各位同事,您好!
我們已將一份精心整理的專業(yè)資料包送達(dá),請(qǐng)您及時(shí)查收。本次資料包共包含 23份文件,內(nèi)容全面覆蓋了前廳運(yùn)營(yíng)的核心領(lǐng)域,旨在幫助團(tuán)隊(duì)系統(tǒng)性地提升服務(wù)品質(zhì),并掌握行業(yè)前沿技術(shù)動(dòng)態(tài)。
一、 資料包核心內(nèi)容概覽
- 服務(wù)流程標(biāo)準(zhǔn)化系列
- 本部分資料詳細(xì)規(guī)定了從客人抵店、入住、在店服務(wù)到離店的全周期標(biāo)準(zhǔn)操作流程(SOP)。
- 涵蓋禮賓、接待、總機(jī)、商務(wù)中心、賓客關(guān)系等各崗位的職責(zé)與協(xié)作節(jié)點(diǎn),確保服務(wù)銜接順暢、高效統(tǒng)一。
- 包含應(yīng)急情況處理預(yù)案,提升團(tuán)隊(duì)?wèi)?yīng)對(duì)突發(fā)事件的綜合能力。
- 崗位培訓(xùn)手冊(cè)匯編
- 針對(duì)新員工入職、在崗技能提升及骨干員工培養(yǎng),設(shè)計(jì)了階梯式培訓(xùn)課程與考核標(biāo)準(zhǔn)。
- 手冊(cè)融合了理論要點(diǎn)、情景模擬、案例分析及實(shí)操練習(xí),形式生動(dòng),便于學(xué)習(xí)和內(nèi)化。
- 特別強(qiáng)調(diào)服務(wù)意識(shí)、溝通技巧與個(gè)性化服務(wù)能力的培養(yǎng)。
- 新材料與新技術(shù)推廣服務(wù)指南
- 此部分聚焦行業(yè)創(chuàng)新,介紹了當(dāng)前適用于前廳場(chǎng)景的新型材料(如環(huán)保裝飾材料、耐用型耗材)與智能技術(shù)(如自助入住設(shè)備、客房控制系統(tǒng)、AI客服助手、數(shù)字禮賓服務(wù)等)。
- 詳細(xì)闡述了各項(xiàng)技術(shù)的應(yīng)用場(chǎng)景、優(yōu)勢(shì)分析、潛在效益及初步實(shí)施建議,為部門未來的服務(wù)升級(jí)與效率革新提供前瞻性參考。
- 包含供應(yīng)商信息、技術(shù)對(duì)比及簡(jiǎn)易維護(hù)知識(shí),助力團(tuán)隊(duì)了解并擁抱行業(yè)變革。
二、 使用建議
- 系統(tǒng)學(xué)習(xí):建議部門組織專題學(xué)習(xí)會(huì),分模塊對(duì)資料進(jìn)行解讀和討論。
- 對(duì)標(biāo)實(shí)踐:將標(biāo)準(zhǔn)流程與現(xiàn)有工作對(duì)照,優(yōu)化細(xì)節(jié),實(shí)現(xiàn)服務(wù)標(biāo)準(zhǔn)化。
- 技術(shù)探索:鼓勵(lì)團(tuán)隊(duì)成員,特別是領(lǐng)班及以上管理人員,深入研究新技術(shù)指南,思考其與本崗位工作的結(jié)合點(diǎn),并提出試點(diǎn)建議。
- 持續(xù)反饋:在使用過程中,歡迎各位結(jié)合實(shí)操經(jīng)驗(yàn),提出修改與增補(bǔ)建議,使資料庫不斷完善。
三、 后續(xù)支持
我們后續(xù)將根據(jù)需要,安排針對(duì)性的培訓(xùn)講座或?qū)嵅俟ぷ鞣唬钊胫v解資料中的重點(diǎn)與難點(diǎn)。請(qǐng)團(tuán)隊(duì)負(fù)責(zé)人協(xié)調(diào)好學(xué)習(xí)時(shí)間,并鼓勵(lì)大家積極利用這份“工具包”,將知識(shí)轉(zhuǎn)化為卓越的服務(wù)體驗(yàn)與運(yùn)營(yíng)效能。
這份資料包是團(tuán)隊(duì)專業(yè)成長(zhǎng)的寶貴資源。請(qǐng)大家妥善保管,認(rèn)真學(xué)習(xí),共同推動(dòng)我們前廳部的服務(wù)水平邁向新高度!
如有任何疑問,請(qǐng)及時(shí)與培訓(xùn)部或相關(guān)部門聯(lián)系。